The Swarm #

A swarm after defeating Brock.
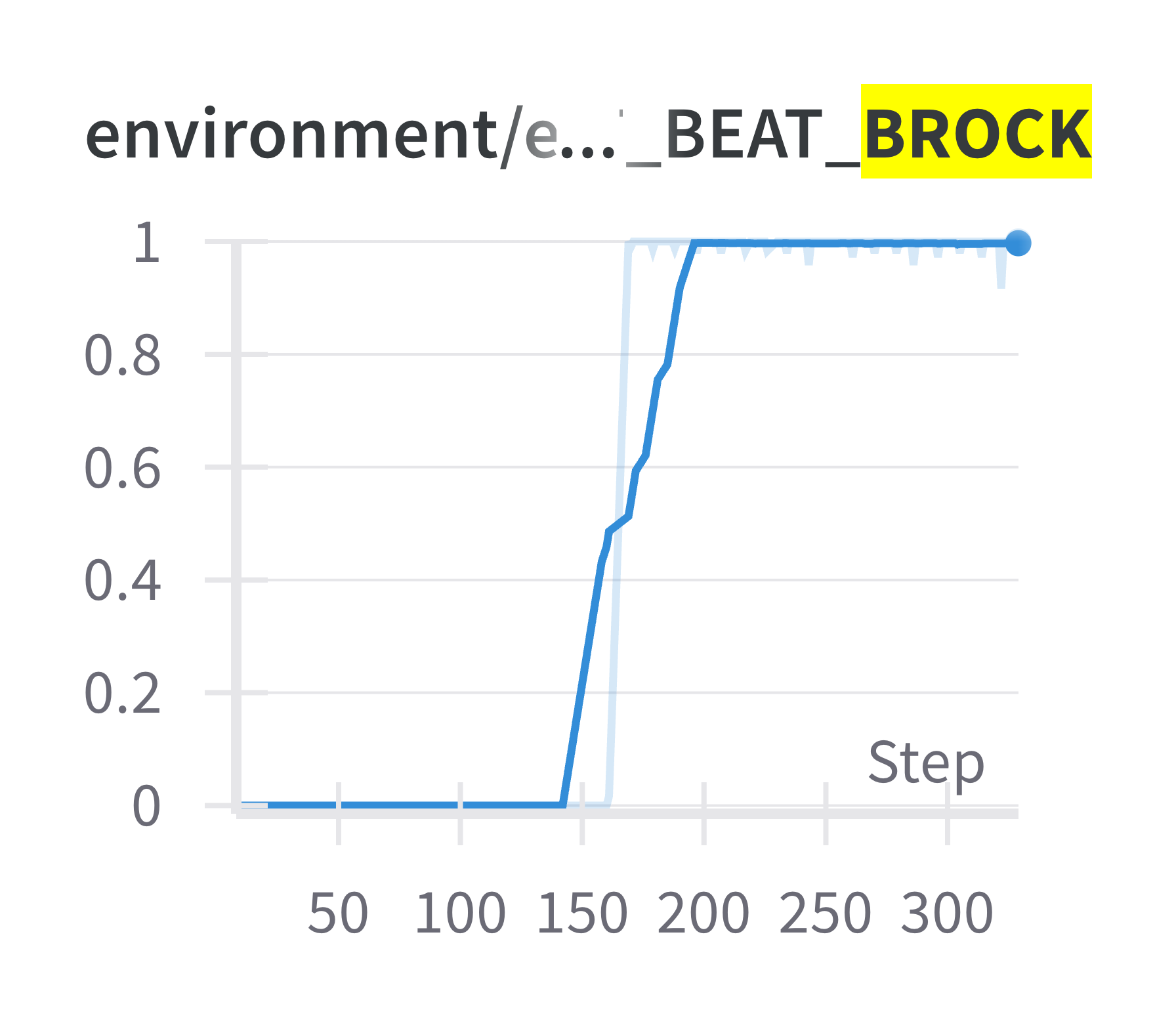
The corresponding metric in Wandb.
We have not mentioned an important modification made to RL loop. Pokémon is a nearly open world game. During training, agents can be in wildly different parts of the game. Consequentially, the experience data can become too random for training a policy.
Without sufficiently predictable data, the policy will not improve. This plagued us for months. Eventually, with inspiration from the Go-Explore paper, we changed our training process to make assurances that the data would remain predictable.
We began recording the save state every time an agent met a required game objective. Every time an agent completed a required objective, every agent loads the save state from the agent that completed the new objective. We tried a variety of other heuristics for when to trigger a swarm and how many environments should participate in the swarm, but this method worked the best. We dubbed this method swarming. Swarming maintains temporal and spatial closeness of agents, thereby ensuring the training data stays predictable.
Unfortunately, swarming means agents may not generalize. To account for this, we reset our save state tracker every time the game is won. As mentioned in the beginning, traditionally in RL, an agent will create actions for independent environments for multiple episodes. Swarming inverts this. We instead run multiple very long episodes of cooperative environments.