Rewards #
Unlike observations, we were a little more flexible with rewards with respect to leaking information to the agent. Event rewards are too sparse. It can be thousands of steps before a high value event is met. The agent needs some way knowing it is making progress in between these high value sparse rewards.
Our reward function (contains over 25 parameters!)
class ObjectRewardRequiredEventsMapIds(BaselineRewardEnv):
def get_game_state_reward(self) -> dict[str, float]:
_, wBagItems = self.pyboy.symbol_lookup("wBagItems")
numBagItems = self.read_m("wNumBagItems")
bag_item_ids = set(self.pyboy.memory[wBagItems : wBagItems + 2 * numBagItems : 2])
return (
{
"cut_tiles": self.reward_config["cut_tiles"] * sum(self.cut_tiles.values()),
"event": self.reward_config["event"] * self.update_max_event_rew(),
"seen_pokemon": self.reward_config["seen_pokemon"] * np.sum(self.seen_pokemon),
"caught_pokemon": self.reward_config["caught_pokemon"]
* np.sum(self.caught_pokemon),
"obtained_move_ids": self.reward_config["obtained_move_ids"]
* np.sum(self.obtained_move_ids),
"hm_count": self.reward_config["hm_count"] * self.get_hm_count(),
"level": self.reward_config["level"] * self.get_levels_reward(),
"badges": self.reward_config["badges"] * self.get_badges(),
"valid_cut_coords": self.reward_config["valid_cut_coords"]
* len(self.valid_cut_coords.values()),
"invalid_cut_coords": self.reward_config["invalid_cut_coords"]
* len(self.invalid_cut_coords.values()),
"start_menu": self.reward_config["start_menu"] * self.seen_start_menu,
"pokemon_menu": self.reward_config["pokemon_menu"] * self.seen_pokemon_menu,
"stats_menu": self.reward_config["stats_menu"] * self.seen_stats_menu,
"bag_menu": self.reward_config["bag_menu"] * self.seen_bag_menu,
"explore_hidden_objs": sum(self.seen_hidden_objs.values()),
"explore_signs": sum(self.seen_signs.values())
* self.reward_config["explore_signs"],
"seen_action_bag_menu": self.seen_action_bag_menu
* self.reward_config["seen_action_bag_menu"],
"pokecenter_heal": self.pokecenter_heal * self.reward_config["pokecenter_heal"],
"rival3": self.reward_config["required_event"]
* int(self.read_m("wSSAnne2FCurScript") == 4),
"game_corner_rocket": self.reward_config["required_event"]
* float(self.missables.get_missable("HS_GAME_CORNER_ROCKET")),
"saffron_guard": self.reward_config["required_event"]
* float(self.flags.get_bit("BIT_GAVE_SAFFRON_GUARDS_DRINK")),
"lapras": self.reward_config["required_event"]
* float(self.flags.get_bit("BIT_GOT_LAPRAS")),
"a_press": len(self.a_press) * self.reward_config["a_press"],
"warps": len(self.seen_warps) * self.reward_config["explore_warps"],
"use_surf": self.reward_config["use_surf"] * self.use_surf,
"exploration": self.reward_config["exploration"] * np.sum(self.reward_explore_map),
"safari_zone": sum(
self.reward_config["safari_zone"] * v for k, v in self.safari_zone_steps.items()
)
/ 502.0,
"use_ball_count": self.reward_config["use_ball_count"] * self.use_ball_count,
"pokeflute_tiles": self.reward_config["pokeflute_tiles"]
* sum(self.pokeflute_tiles.values()),
"surf_tiles": self.reward_config["surf_tiles"] * sum(self.surf_tiles.values()),
"valid_pokeflute_coords": self.reward_config["valid_pokeflute_coords"]
* len(self.valid_pokeflute_coords.values()),
"invalid_pokeflute_coords": self.reward_config["invalid_pokeflute_coords"]
* len(self.invalid_pokeflute_coords.values()),
"valid_surf_coords": self.reward_config["valid_surf_coords"]
* len(self.valid_surf_coords.values()),
"invalid_surf_coords": self.reward_config["invalid_surf_coords"]
* len(self.invalid_surf_coords.values()),
}
| {
event: self.reward_config["required_event"] * float(self.events.get_event(event))
for event in REQUIRED_EVENTS
}
| {
item.name: self.reward_config["required_item"] * float(item.value in bag_item_ids)
for item in REQUIRED_ITEMS
}
| {
item.name: self.reward_config["useful_item"] * float(item.value in bag_item_ids)
for item in USEFUL_ITEMS
}
)Sparse vs. Dense Rewards #
Sparse rewards are high value rewards, but rarely occur, e.g. gym battles. If we were to only reward the sparse rewards, the agent would never leave the starting point in Pallet Town.
Dense rewards are like breadcrumbs; they occur frequently but with much lower value than a sparse reward. Dense rewards teach the agent how to explore or interact with the world. With dense rewards, the agent can progress and eventually discover the highly valued sparse rewards.
Is Exploration All You Need? #
Exploration was the foundation for all dense rewards.
We originally believed that an agent had successfully learned Pokémon if the agent could visit every coordinate in the game’s world. However, we couldn’t only use exploration rewards. If we were to only reward unique coordinates, the agent never interacts with Brock. Instead, the agent wanders the world forever collecting new locations until it runs out of locations. We loosened our definition. Now, we consider any interaction a form of exploration.
In the end, we rewarded:
- The number of unique coordinates visited during a mini-episode.
- The number of signs the agent interacts with during a mini-episode.
- The number of objects the agent interacts with during a mini-episode.
- The number of unique moves taught.
- The number of valid and invalid uses of HMs/Pokéflute in the overworld.
- The number of tile types an HM/Pokéflute was used on.
- The number of unique map ID transitions (warps) visited during a mini-episode.
- The number of unique seen and caught Pokémon.
We also experimented with rewarding for all locations an agent has pressed the A button (you make selections in Pokémon by pressing A) on and the number of unique menus the agent has visited during an episode. However, the A press and unique menus rewards provided little gain and slowed down training tremendously because the agent would frequently press A instead of focusing on navigation.
Making Game Progress? #
Game progress is defined by accomplishing high value, sparse rewards. These include:
- All required events completed. A required event is an event required to beat the game. Pokémon has around 80 required events.
- All required items obtained. HMs are an example of required items.
- All useful but not required items obtained. The Bicycle is an example of a useful item.
Without these rewards, the agent would ultimately wander until the mini-episode reset and make no progress.
Map ID Rewards #
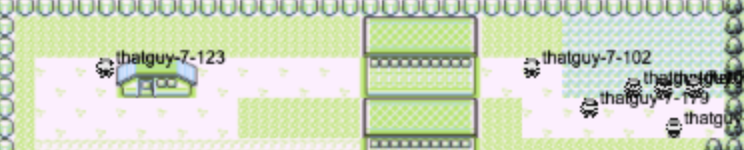
Lots of agents exploring the area where you can get HM02.
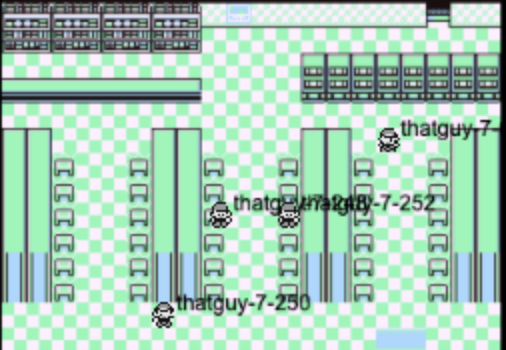
Lots of agents exploring the Celadon Game Corner. The agent liked to exploit the object reward the slot machines provided. Sometimes the agent even obtained an Abra.
We observed that in order to “solve” all events on a map (a map is the currently loaded game area, e.g., town, route, cave floor, etc.), we needed around 10-20 environments exploring the map. For Pokémon, 10-20 agents map to around 10% map ID coverage.
We regretfully “boosted” coordinates reward if the agent explored a currently important map ID. On one hand, we are potentially putting the game on rails. On the other hand, we experienced that the agent would not focus on important areas, e.g., Rocket Hideout, unless we boosted rewards for specific map IDs.
Specific map IDs start the game with a boosted exploration reward until the map ID’s objective is complete. For example, a gym has a boosted reward until it is beaten. Only two map IDs break this rule.
- Route 23 (where the Rival 6 battle occurs) does not get boosted until all gyms are beaten.
- Lavender Tower does not get boosted until Giovanni is defeated in Rocket Hideout and the Silph Scope is acquired. Otherwise, agents do not leave Lavender due to the level up reward obtained from the wild battles inside Lavender Tower.
We believe we would not need these rewards if the agent could understand text. Often in Pokémon, an NPC will give hints to the player as to where to go next. Our agent could not parse text and therefore would obviously not know where to go.
Safari Zone Rewards #
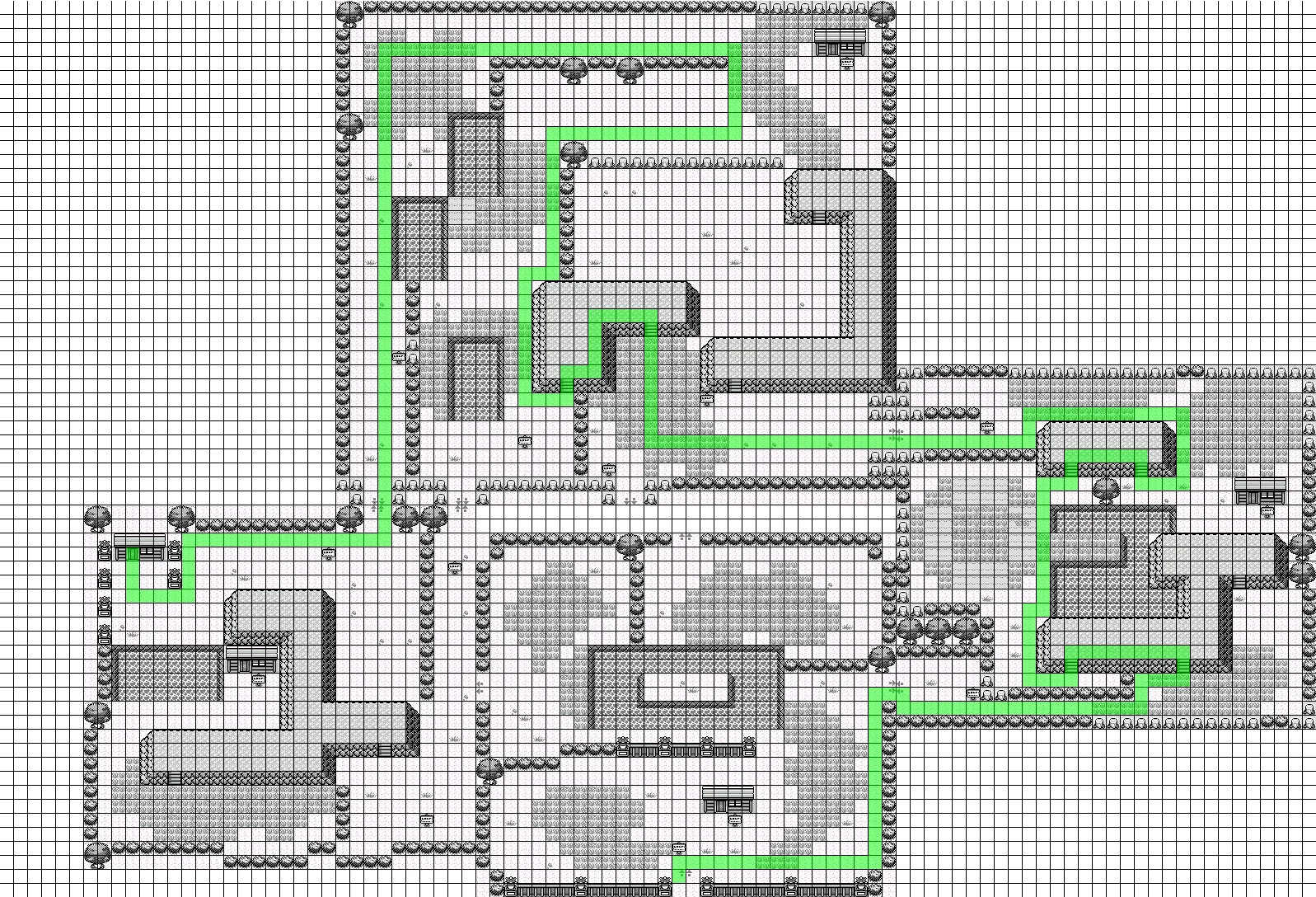
The green route will lead the player to the required items in the Safari Zone. In the north area, there is a fork in the road that often confuses the agent.
The Safari Zone minigame provided a big challenge. The Safari Zone is a minigame where two required items must be obtained within 500 steps. The Safari Zone can be attempted as long as you can pay the entrance fee. Safari Zone’s route is pretty linear until a fork in the road 75% the way in. We needed to incentivize the agent to get to that fork as fast as possible and take the correct fork.
We added a specific Safari Zone reward for this case. The agent obtains a reward proportional to the number of steps left for any map ID it reaches within the Safari Zone. Ideally, the agent’s visited mask would prompt the agent to explore both forks within the same episode. In reality, the agent does eventually complete the Safari Zone but it can take thousands of steps during training.
Level Reward #
Peter Whidden suggested a level reward in his video. We took the level reward from Peter Whidden’s video without many changes. Any attempt to remove the reward led to a failed experiment.
The level reward
\[ Reward = \begin{cases} \sum_{i=1}^{6} \text{level}_i & if \sum_{i=1}^6 \text{level}_i < 15 \\ 30 + \frac{\sum_{i=1}^{6} \text{level}_i - 15}{4} & if \sum_{i=1}^6 \text{level}_i >= 15 \end{cases} \]attempts to find a balance between promoting early game leveling and ensuring the agent is focused on exploration over leveling as the game continues.