RL Algorithm and Policy #
For training, we adopted the on-policy algorithm Proximal Policy Optimization (PPO). PPO supports vectorized environments well and there is a large amount of online code examples surrounding it.
We tried to keep the policy itself simple. We wanted a policy that:
- Could have some way of processing sequential (time) data.
- Was small for faster training.
To handle time dependence we considered a few options:
- Stack observations over a time dimension. Then use some form of model that handles batches of sequential data, e.g., a 3D CNN or attention layer. However, the model’s input would linearly increase with the size of the stack. Stacking would have heavily slowed down training and require more VRAM than we have.
- Use a recurrent neural network such as an LSTM.
- Use a state space model (SSM).
We went with the easiest to integrate solution, an LSTM. An LSTM contains an internal state that gets input to the model alongside the most recent data point. In the best case, LSTMs can only remember on the order of 1000 steps. That was enough history for an effective policy.
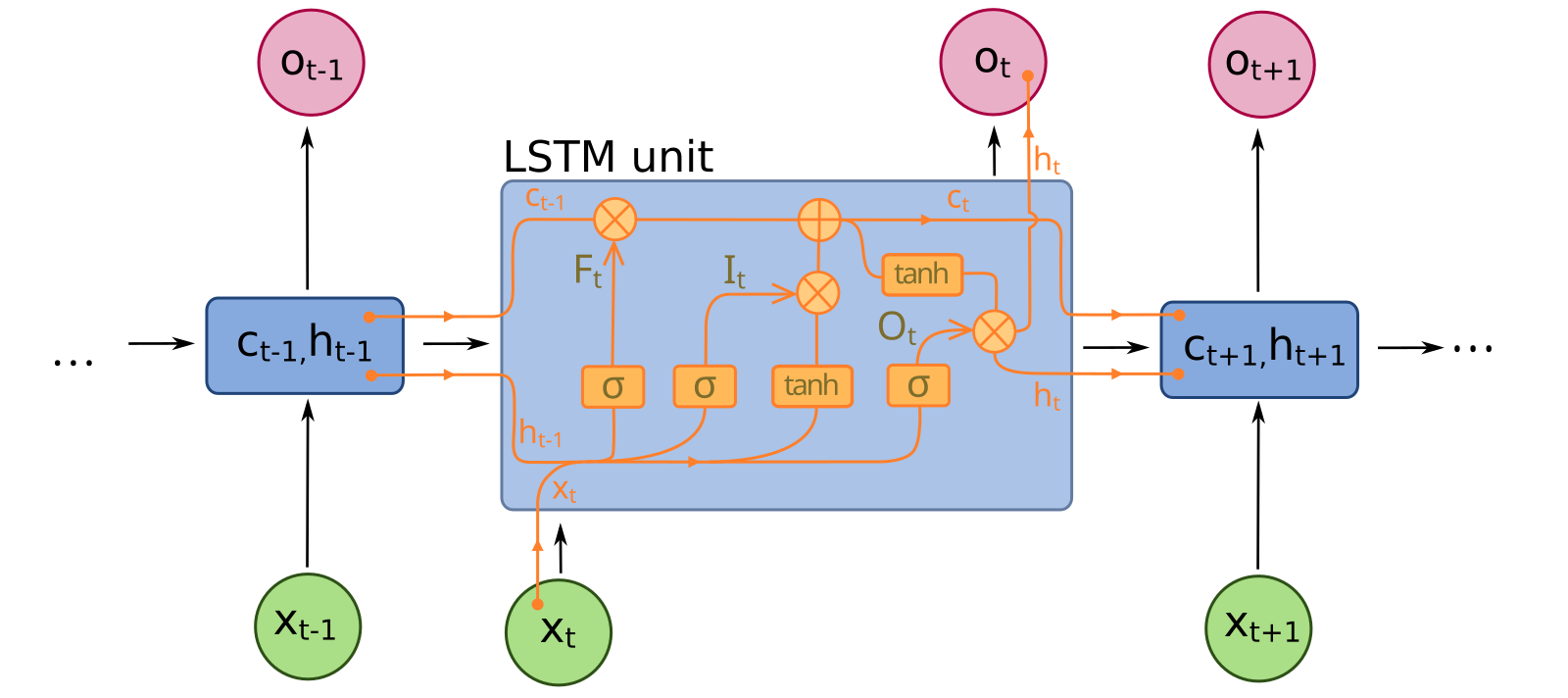
An LSTM cell. The values c and h output by the LSTM are fedback in the subsequent call.
The policy ended up being ≈5M parameters or 20MB. For context, that’s 5 orders of magnitude smaller than Deepseek. Enough to fit on the average consumer GPU 400x over.
Inputting the Observations into the Policy #
In the previous sections we described the observation, but did not go into how each observation is input to the policy. The policy looks large, but it’s really an encoder for the previously described observations, e.g., normalizing continuous data. At the output, everything is concatenated and then input to the LSTM.
Pokémon Red Policy #
Pokémon Red Policy
---
config:
theme: mc
look: handDrawn
---
flowchart LR
Party_Network2["Party Network"]
FinalConcat("Concat")
Screen_Network2["Screen Network"]
MapIDE("Map ID Embeddings
dim=4")
MapID("Map ID")
MapIDE2("Map ID Embeddings
dim=4")
BlackoutMapId("Blackout Map ID")
Mul("x")
ItemIDE("Item ID Embeddings
dim=4")
BagItemIds("Bag Item IDs")
div100("/ 100")
BagItemQ("Bag Item Quantities")
Events("Events Completed Array")
OneHot("One-hot")
Direction("Direction")
OneHot2("One-hot")
BattleT("Battle Type")
MissingEvents2("Missing Events")
div502("/ 502.0")
SafariZoneSteps("Safari Zone Steps Remaining")
LSTM("LSTM
size=128
num cells=1")
Linear3("Linear
size=512")
ReLU4("ReLU")
Party_Network2 --> FinalConcat
Screen_Network2 --> FinalConcat
MapID --> MapIDE
MapIDE --> FinalConcat
BlackoutMapId --> MapIDE2
MapIDE2 --> FinalConcat
BagItemIds --> ItemIDE
ItemIDE --> Mul
BagItemQ --> div100
div100 --> Mul
Mul --> FinalConcat
Events --> FinalConcat
Direction --> OneHot
OneHot --> FinalConcat
BattleT --> OneHot2
OneHot2 --> FinalConcat
MissingEvents2 --> FinalConcat
SafariZoneSteps --> div502
div502 --> FinalConcat
FinalConcat --> Linear3
Linear3 --> ReLU4 --> LSTM
Party Network
---
config:
theme: mc
look: handDrawn
---
flowchart LR
Concat("Concat")
SIDE("Species Embeddings
dim=4")
SID("Species ID")
Hp("HP")
Status("Status")
t1e("Type Embeddings
dim=3")
t1("Type 1")
t2e("Type Embeddings
dim=3")
t2("Type 2")
level("Level")
MaxHp("Max HP")
`ATTACK`("`ATTACK`")
`DEFENSE`("`DEFENSE`")
`SPECIAL`("`SPECIAL`")
MovesE("Moves Embeddings
dim=4")
Moves("Moves")
Flatten1("Flatten")
Linear1("Linear
dim=6")
ReLU("ReLU")
SID --> SIDE
SIDE --> Concat
Hp --> Concat
Status --> Concat
t1 --> t1e
t1e --> Concat
t2 --> t2e
t2e --> Concat
level --> Concat
MaxHp --> Concat
`ATTACK` --> Concat
`DEFENSE` --> Concat
`SPECIAL` --> Concat
Moves --> MovesE
MovesE --> Concat
Concat --> Linear1
Linear1 --> ReLU
ReLU --> Flatten1
Screen Network
---
config:
theme: mc
look: handDrawn
---
flowchart LR
Concat2("Concat")
gamescreen("Game Screen
72x80x1
grayscale")
visitedmask("Visited Mask
72x80")
relu1("ReLU")
Conv1("2D CNN
filters=32
kernel size=8
stride=2")
relu2("ReLU")
Conv2("2D CNN
filters=64
kernel size=4
stride=2")
relu3("ReLU")
Conv3("2D CNN
filters=64
kernel size=3
stride=2")
Flatten2("Flatten")
gamescreen --> Concat2
visitedmask --> Concat2
Concat2 --> Conv1
Conv1 --> relu1
relu1 --> Conv2
Conv2 --> relu2
relu2 --> Conv3
Conv3 --> relu3
relu3 --> Flatten2
Missing Events
---
config:
theme: mc
look: handDrawn
---
flowchart TB
Rival3("Rival 3 Defeated Boolean")
Lapras("Lapras Acquired Boolean")
SaffronGuard("Drink Given Saffron Guard Boolean")
GameCornerRocket("Game Corner Rocket")
Let’s summarize the shape and data type of each observations:
| Observation | Shape | Data Type |
|---|---|---|
| Screen | 72x80x1 | int |
| Visited Mask | 72x80x1 | int |
| Map ID | 1 | int |
| Blackout Map ID | 1 | int |
| Item IDs | 20 | int |
| Item Quantities | 20 | int |
| Agent Party | 6x11 | int |
| Events Array | 2560 | boolean |
| Direction | 1 | int |
| Current Battle Condition | 1 | int |
| Rival 3 Defeated | 1 | boolean |
| Lapras Acquired | 1 | boolean |
| Saffron Guard | 1 | boolean |
| Game Corner Rocket Defeated | 1 | boolean |
| Number of Safari Steps Remaining | 1 | int |
You may notice nodes where we divide by a constant. We normalize some constants so the values will be in the range [0, 1] for model training stability.
The CNN #
The screen obs and visited mask observations are concatenated together to make 2 “channels”. These channels are passed to a 2D Convolutional Neural Network (CNN). The kernel sizes of the CNN are designed with the GameBoy’s tile size (8 pixels) in mind.
One-Hot encoding #
One-hot encoding is a convenient technique to take a value representing a category and map it to a representation a model can understand. It’s useful when the number of categories is low.
Direction and battle state (in-battle, wild battle, trainer battle) are transformed to their one-hot encoded values.
Embeddings #
The map ID and blackout map IDs come from the environment as integers, but are transformed before input to the embedding layer. Embedding layers are a convenient way of representing categorical input in a low-dimensional space. Instead of one-hot encoding the map ID (255 dimensions), we use 4 floats to represent the map ID space. We chose 4 based on a recommendation from Google’s Machine Learning Crash Course. Google recommends using (# of categories)^.25 for the number of dimensions in an embedding layer.
Items held in the agent’s bag are also identified by ID. The Item IDs are passed to their own embedding layer. We scale the item embeddings by the item’s quantities; rersulting in a number between 0 and 1 where 0 maps to not in the bag and 1 maps the max number of the same item an agent can have.
Party Network #
All party data is concatenated together and passed through a small dense layer to create a “Pokémon” space.
Binary Vectors #
In RAM, events are stored as a 320-byte array with each bit optionally representing one in-game event. We unpack this aray into a 2560-byte vector, filter for flags that are used by the game and pass the vector to the policy. The event vector in RAM does not include Lapras, Rival 3, defeating the Game Corner Rocket and giving a drink to a Saffron Guard. We additionally pass these 4 “events” to the policy as they are “event”-like in our opinion.
Safari Steps #
The numbers of steps left in the Safari Zone is in the range [0, 502]. We normalize the steps observation to a value between 0 and 1 where 0 means no steps are left and 1 means you have the max number of steps remaining.
Final Model Layers #
Once all features have been transformed, all non-batch dimension data is flattened, concatenated and passed through a final linear layer before heading to the LSTM.